Flavors of Ruby on Rails Architectures
I gave this talk at the SF Bay Area Ruby meetup on Sep 3rd, 2024, at GitHub HQ in San Francisco.


Hi, I’m Kamil Nicieja, and today I’ll be discussing the various types of Ruby on Rails architectures.

But first, let me share a bit about myself. I’m currently the lead software engineer at Plane, a Y Combinator startup. In the past, I’ve co-founded a few startups myself and authored books on testing and product management. I recently moved to San Francisco, just two months ago, so I wanted to say hello and ask—what’s the preferred flavor of Rails around here?

Let's start with vanilla Rails, the starting point for most developers.

This part will be pretty straightforward, but it’s important to set a baseline. We have a model, some concerns, callbacks—the usual components that everyone is familiar with because it’s the Rails way, taught to most of us when we’re just starting out.

In vanilla Rails, the models are often “rich,” meaning they contain a lot of code. To manage this, much of the code is typically extracted into concerns. For example, you can see a straightforward part of a model moved into a role concern.

Here’s a more complex example. Since we’re at GitHub HQ, I thought this would be a fitting choice. In this example, we have a Repository model with a Pull concern that allows you to fetch git repositories from the API, along with the commits. This shows that it’s not just simple tasks that can be handled with this approach—pretty much anything can be managed this way.

Now, with this approach, we might encounter a problem: what if we have some code that interacts with multiple models but doesn’t naturally fit into any of them? 37signals addresses this by placing such transaction scripts into separate domain concepts and treating them as models as well. This way, it becomes another noun in the ubiquitous language of the domain.

The biggest benefit of this approach is that it’s fully supported out of the box and is part of Rails’ well-known magic: it just works.

Let’s move on to the second approach. I briefly mentioned it earlier when I talked about transaction scripts. This approach builds on that concept, and I like to call it service-oriented Rails.

When working with vanilla Rails, some developers find that the standard approach tends to overload the models with too much code. To address this, they look for clearer, more refined abstractions, leading them to start experimenting with different approaches.
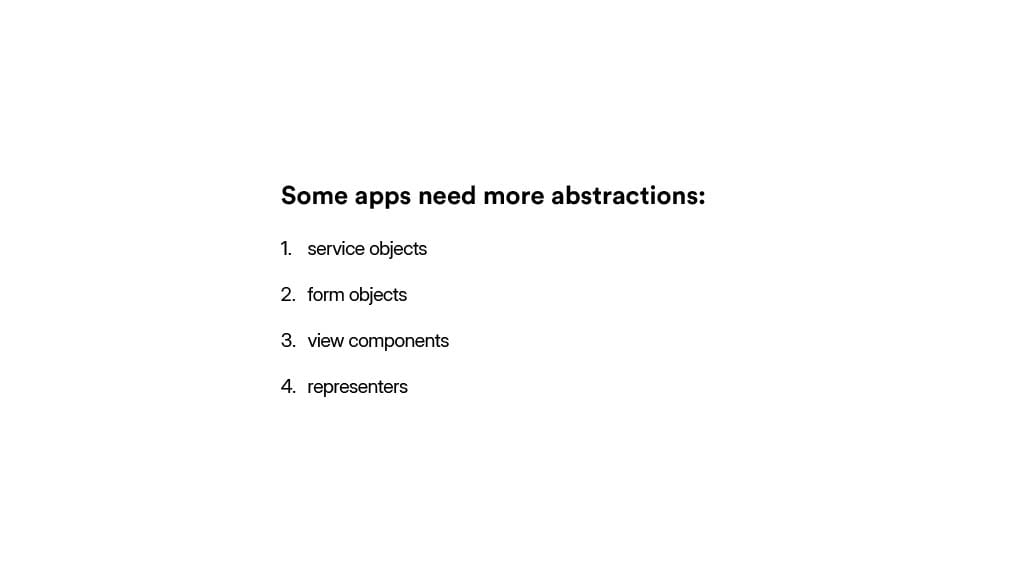
They likely end up with something like this: services, form objects, view components, and representers for handling views and APIs.

This is actually the approach we’re currently using at Plane, and we’ve even developed our own custom library to support our specific needs. I’m going to give you a quick look at it. Unfortunately, it’s not open source, but if you’re interested in this kind of approach, there are similar options available, like the Trailblazer framework or the dry-rb stack.

Let’s start from the basics. We define a simple service object, which we refer to as an “operation."
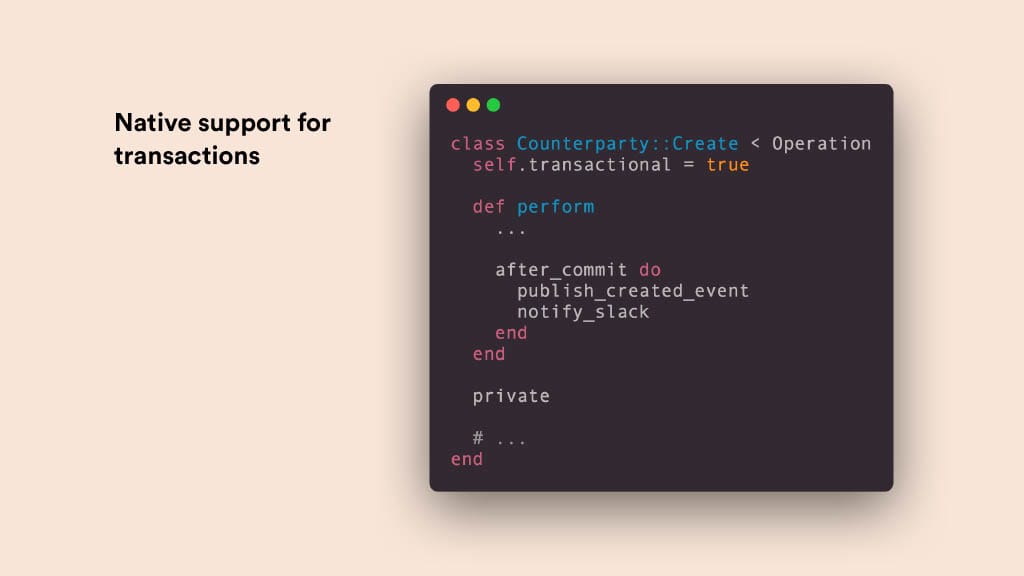
At Plane, we typically wrap all our operations in transactions and manage side effects using after_commit blocks. In this example, I’ve explicitly made the operation transactional to demonstrate how it works. If I wanted to create a non-transactional operation, such as one that interacts with an external API, I would simply set transactional to false.
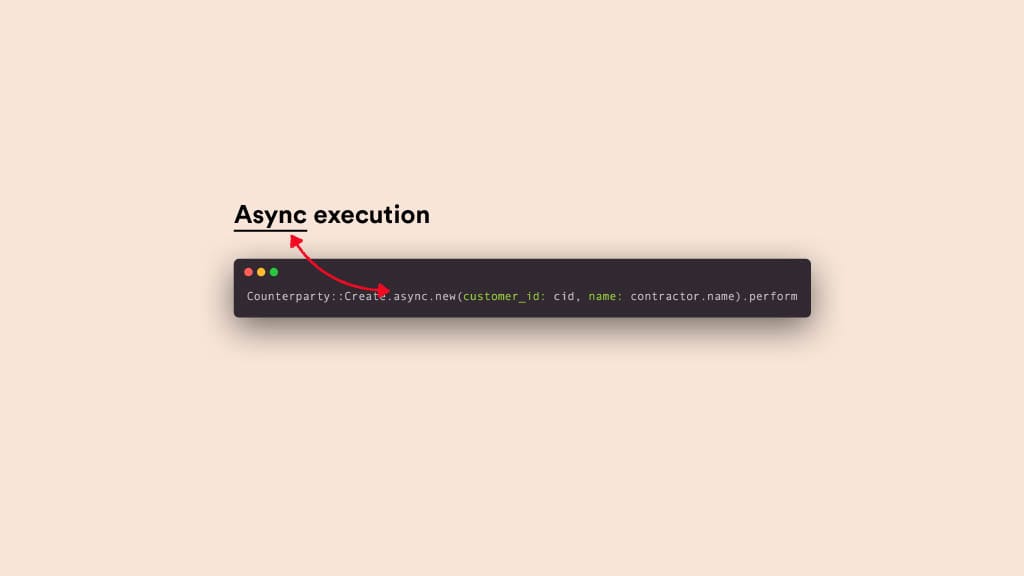
All operations can be called asynchronously by simply adding the async prefix to the chain. This feature is quite useful, as it helps you avoid the boilerplate code associated with background jobs that only exist to call other service objects.

Another great feature is the built-in support for typed parameters. As you can see here, we use a Params struct to explicitly define all the arguments that the operation can take, along with their types and even default values.

Similarly, responses can be typed as well.

Now, let’s talk about recording operations. This feature is particularly useful for debugging or meeting compliance requirements. Parameters and results are stored in a database table, allowing you to easily track and review the operations that have been executed.

Another handy feature of our library is the ability to ensure an operation is performed only once by using a nonce key. In this example, the operation is executed just once, and any subsequent attempts with the same key will simply retrieve the previously recorded response.

We also support remote operations that can communicate across multiple microservices. In the example, you can see that by adding a remote method at the top, the operation acts as a server, making it available as an RPC over RabbitMQ.

Here’s the client-side call, which we can make from another Rails app. By adding the remote prefix to the chain when initializing the operation, the library handles all the communication between services. You can simply enjoy the result without worrying about the underlying complexity.

That wraps it up. While none of this is groundbreaking, it’s still a powerful, simple, and flexible architecture that extends the vanilla Rails approach without being disruptive. The main downside we’ve encountered is that by making operations so convenient, engineers may start relying on them for almost everything. In vanilla Rails, we had the issue of overloaded models, and here, we risk ending up with anemic models that only store basic data and overloaded operations. So, it’s important to stay mindful of design and use this approach thoughtfully.

Time for the third approach, domain-driven Rails.

Alright, so we’ve covered two patterns so far, but we haven’t ventured too far from classic Rails architectures yet. One of the main challenges with Rails is that, over time, it tends to encourage tight coupling. If you’re not careful, everything starts talking to everything else, and making changes becomes difficult because you end up needing to refactor half the system.
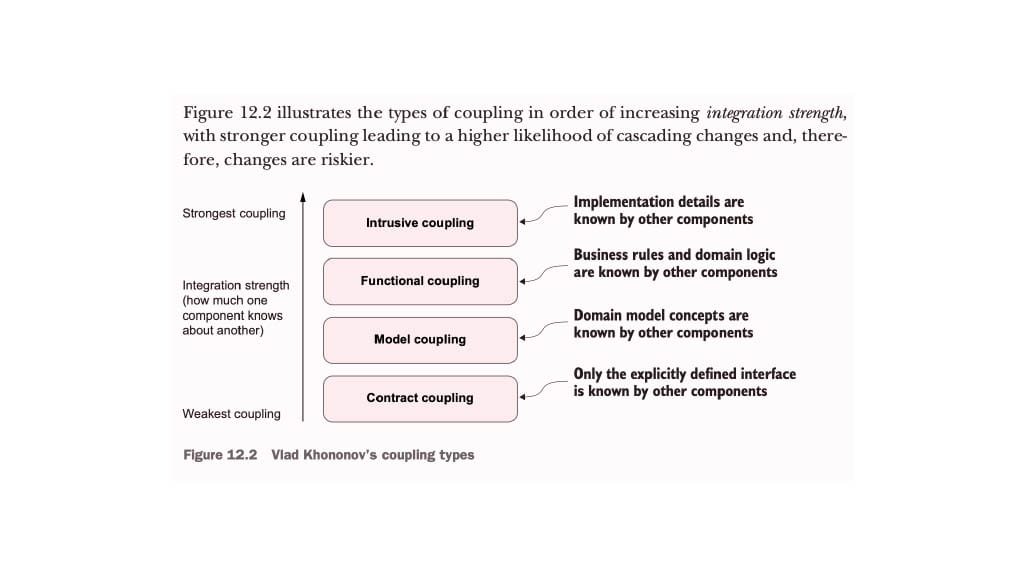
That figure is from a book called “Architecture Modernization” by Nick Tune, where I served as the technical editor. Unfortunately, Rails tends to land at the top of the diagram, characterized by strong and sometimes intrusive coupling.

Here’s the book if you're interested. It’s a great read, though I might be a bit biased!

So now, let’s take this problem and its solution to the extreme by decoupling as much as possible. In the upcoming code samples, I’ll be using a gem called rails-event-store to demonstrate how this works.

We’ll begin by introducing the command pattern into our codebase. Here, we use a command bus to execute a command.

The goal here is to decouple the action from the actor. Now, multiple handlers from different subsystems can respond to our commands, and we don’t need to worry about their responses. Our job is done once we’ve communicated what we need.

Next, we add a command handler. This handler is responsible for building what's known as an aggregate root.

As you can see, an aggregate root is a pure Ruby class that represents our domain model. The key distinction here is that it’s not an Active Record model. Another important aspect is that the state of the model is derived from events. When our command triggers the add_item method, this method fires an event, and the model’s state is constructed from a sequence of events. This is all part of the decoupling process. For example, we could have a non-Ruby system sending these events, and it would still be compatible with our domain and the code.

Now, you might wonder how we use this in our application layer since it’s completely separated from the domain layer. The answer lies in building a bridge called a read model. A read model is an Active Record model that we create in response to an event. Once created, we can use it just like any other vanilla Rails model. The advantage of this approach is that the read model can be optimized specifically for whatever we need in the view. For example, in this simple case, I’m setting the status to “Submitted,” which could be directly displayed in the view.

Alright, let’s weigh the pros and cons. On the plus side, this approach aligns well with event-driven programming, making it a good fit for microservices-based architectures. It’s also quite reusable—you could, for example, develop a decoupled billing domain once and reuse it across multiple apps. Additionally, because of the loose coupling, it’s more resistant to changes.
However, the downside is the complexity we’ve just introduced. I mean, did you see that code? Something as straightforward as adding an item to a basket suddenly feels as challenging as a journey to Mordor. The reality is that CRUD architectures are almost always good enough for most applications.

📣 Before Growth has grown through word of mouth. Want to help? Share it on Twitter here, Facebook here, or LinkedIn here.

The future of tech, direct to your inbox
Discover the next generation. Subscribe for hand-picked startup intel that’ll put you ahead of the curve, straight from one founder to another.



{kind=link}